Exploring Linked Lists in Data Structures and Algorithms
Introduction to Linked List
Linked lists are the new data structure we'll explore today. The study of linked lists will certainly be detailed, but first, I would like to inform you about one of the fundamental differences between linked lists and arrays.
Arrays demand a contiguous memory location. Lengthening an array is not possible. We would have to copy the whole array to some bigger memory location to lengthen its size. Similarity inserting or deleting an element causes the elements to shift right and left, respectively.
But linked lists are stored in a non-contiguous memory location. To add a new element, we just have to create a node somewhere in the memory and get it pointed by the previous element. And deleting an element is just as easy as that. We just have to skip pointing to that particular node. Lengthening a linked list is not a big deal.
Structure of a Linked List:
Every element in a linked list is called a node and consists of two parts, the data part, and the pointer part. The data part stores the value, while the pointer part stores the pointer pointing to the address of the next node.
Both of these structures (arrays and linked lists) are linear data structures.
Linked Lists VS Arrays:
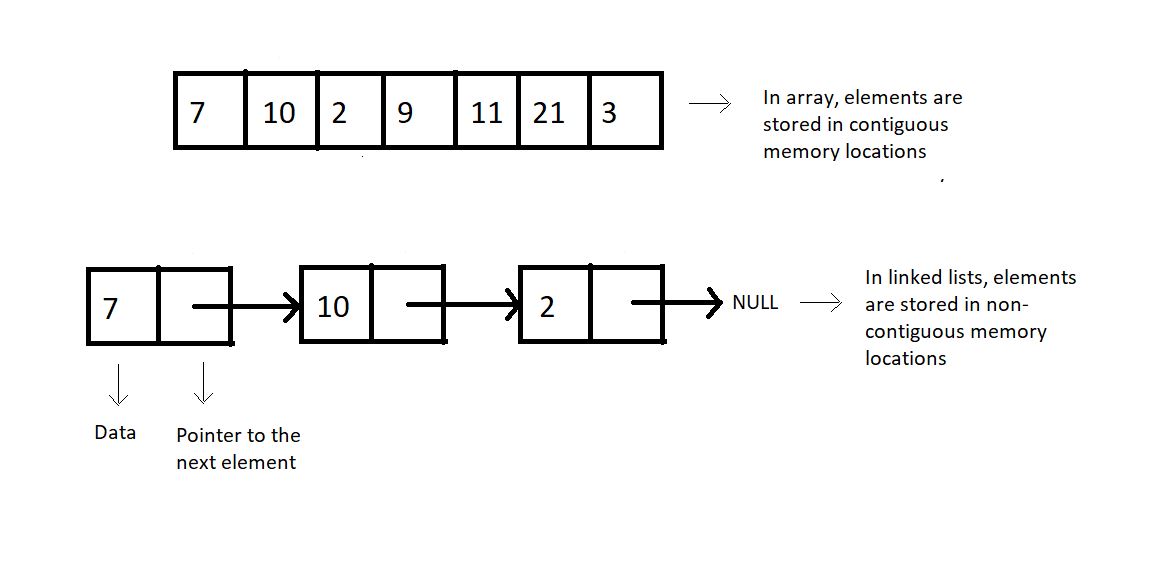
this figure shows how linked lists differ then arrays
Why Linked Lists?
Memory and the capacity of an array remain fixed, while in linked lists, we can keep adding and removing elements without any capacity constraint.
Drawbacks of Linked Lists:
Extra memory space for pointers is required (for every node, extra space for a pointer is needed)
Random access is not allowed as elements are not stored in contiguous memory locations.
Creation of Linked list in C Language
Linked lists are implemented in C language using a structure. You can refer to the code below.
Understanding the code below:
We construct a structure named Node.
Define two of its members, an integer data which holds the node's data, and a structure pointer, next, which points to the address of the next structure node.
struct Node {
int data;
struct Node *next; // Self referencing structure
};
Code 1: Implementation of a linked list
These were just the basics of the linked lists.
An element in a linked list is a struct Node. It is made to hold integer data and a pointer of data type struct Node\, as it has to point to another struct Node.*
We’ll create the below illustrated linked list.

We will always create individual nodes and link them to the next node via the arrow operator ‘→’.
First, we’ll define a structure Node and create two of its members, an int variable data, to store the current node's value and a struct node* pointer variable next.
Now, we can move on to our main() and start creating these nodes. We’ll name the first node, head. Define a pointer to head node by struct node\ head.* And similarly for the other nodes. Request the memory location for each of these nodes from heap via malloc using the below code.
head = (struct Node *)malloc(sizeof(struct Node));
Traversal of Linked list in C Language
Traversal in a linked list means visiting each element in the list. This allows us to print all the elements of the linked list.
For traversal in a linked list, first, we have to create a void function with any name, like _linkedlistTraversal_, and pass the pointer to the head node into it.
Run a while loop as long as the pointer doesn’t point to NULL. Keep changing the pointer to next each time you finish printing the data of the current node.
You can understand it better with the code below:
void linkedListTraversal(struct Node *ptr) {
while (ptr != NULL) {
printf("Element: %d\n", ptr->data); ptr = ptr->next;
} }
int main() {
struct Node head;
struct Node second;
struct Node third;
struct Node fourth; (you can more node if you want more long linked list)
// Allocate memory for nodes in the linked list in Heap
head = (struct Node )malloc(sizeof(struct Node));
second = (struct Node )malloc(sizeof(struct Node));
third = (struct Node )malloc(sizeof(struct Node));
fourth = (struct Node )malloc(sizeof(struct Node));
// Link first and second nodes
head->data = 7;
head->next = second;
// Link second and third nodes
second->data = 11;
second->next = third;
// Link third and fourth nodes
third->data = 41;
third->next = fourth;
// Terminate the list at the third node
fourth->data = 66;
fourth->next = NULL;
linkedListTraversal(head);
return 0;
}
Inserting in a linked list
When we need to insert a new element into a linked list, we have some categories for inserting a new element into a linked list:
Case 1: Insert at the beginning -> Time complexity: O(1)
Case 2: Insert in between -> Time complexity: O(n)
Case 3: Insert at the end -> Time complexity: O(n)
Case 4: Insert after the node -> Time complexity: O(1)
To insert a new element into the linked list, we first need to create an extra node. Then, we update the current connections and establish new ones. This is how we insert a new node at the desired position.
Syntax for creating a node:
struct Node ptr = (struct Node) malloc (sizeof (struct Node))
The above syntax will create a node, and the next thing one would need to do is set the data for this node.
ptr->data = data (the value you want)
This will set the data.
Now, let's start with each of these insertion cases.
Case 1: Insert at the beginning
To insert a new node at the beginning, we need to make the head pointer point to this new node and set the new node’s pointer to the current head.

Create a struct Node* function insertAtFirst which will return the pointer to the new head.
We’ll pass the current head pointer and the data to insert at the beginning, in the function.
Create a new struct Node* pointer ptr, and assign it a new memory location in the heap.
Assign head to the next member of the ptr structure using ptr-> next = head, and the given data to its data member.
Return this pointer ptr
You will understand better with the code below:
struct Node insertAtFirst(struct Node head, int data) {
struct Node ptr = (struct Node ) malloc(sizeof(struct Node));
ptr->data = data;
ptr->next = head;
return ptr;
}
Case 2: Insert in between:
Assuming index starts from 0, we can insert an element at index i>0 as follows:
Bring a temporary pointer p pointing to the node before the element you want to insert in the linked list.
Since we want to insert between 8 and 2, we bring pointer p to 8.

Create a struct Node* function insertAtIndex which will return the pointer to the head.
We’ll pass the current head pointer and the data to insert and the index where it will get inserted, in the function.
Create a new struct Node* pointer ptr, and assign it a new memory location in the heap.
Create a new struct Node* pointer pointing to head, and run a loop until this pointer reaches the index, where we are inserting a new node.
Assign p->next to the next member of the ptr structure using ptr-> next = p->next, and the given data to its data member.
Break the connection between p and p->next by assigning p->next the new pointer. That is, p->next = ptr.
Return head.
You will understand better with the code below:
struct Node insertAtIndex(struct Node head, int data, int index){
struct Node ptr = (struct Node*) malloc(sizeof(struct Node));
struct Node * p = head;
int i = 0;
while (i!=index-1) {
p = p->next;
i++;
}
ptr->data = data;
ptr->next = p->next;
p->next = ptr;
return head;
}
Case 3: Insert at the end:
In order to insert an element at the end of the linked list, we bring a temporary pointer to the last element.
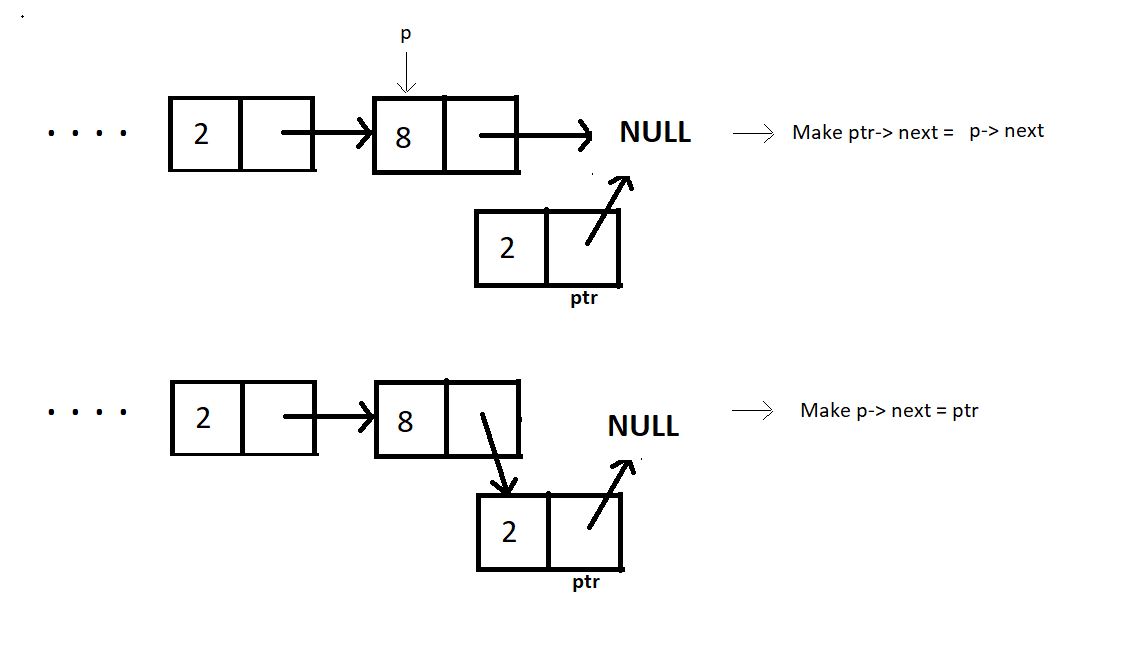
Inserting at the end is very similar to inserting at any index. The difference holds in the limit of the while loop. Here we run a loop until the pointer reaches the end and points to NULL.
Assign NULL to the next member of the new ptr structure using ptr-> next = NULL, and the given data to its data member.
Break the connection between p and NULL by assigning p->next the new pointer. That is, p->next = ptr.
Return head.
You will understand better with the code below:
struct Node insertAtEnd(struct Node head, int data){
struct Node ptr = (struct Node ) malloc(sizeof(struct Node));
ptr->data = data;
struct Node * p = head;
while(p->next!=NULL){
p = p->next;
}
p->next = ptr;
ptr->next = NULL;
return head;
}
Case 4: Insert after a node:
Similar to the other cases, ptr can be inserted after a node as follows:
ptr->next = prevNode-> next;
prevNode-> next = ptr;
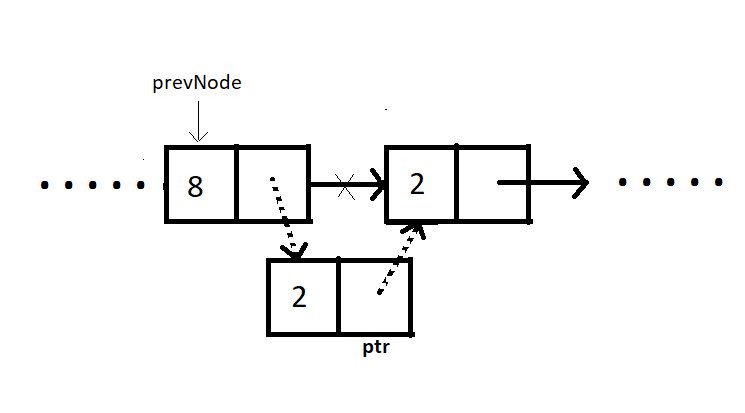
Here, we already have a struct Node* pointer to insert the new node just next to it.
Create a struct Node* function insertAfterNode which will return the pointer to the head.
Pass into this function, the head node, the previous node, and the data.
Create a new struct Node* pointer ptr, and assign it a new memory location in the heap.
Since we already have a struct Node* prevNode given as a parameter, use it as p we had in the previous functions.
Assign prevNode->next to the next member of the ptr structure using ptr-> next = prevNode->next, and the given data to its data member.
Break the connection between prevNode and prevNode->next by assigning prevNode->next the new pointer. That is, prevNode->next = ptr.
Return head.
You will understand better with the code below:
struct Node insertAfterNode(struct Node head, struct Node prevNode, int data){
struct Node ptr = (struct Node ) malloc(sizeof(struct Node));
ptr->data = data;
ptr->next = prevNode->next;
prevNode->next = ptr;
return head;
}
Deletion in linked list
When we need to delete a new element into a linked list, we have some categories for deleting element into a linked list:
Case 1: Deleting the first node -> Time complexity: O(1)
Case 2: Deleting the node at the index -> Time complexity: O(n)
Case 3: Deleting the last node -> Time complexity: O(n)
Case 4: Deleting the first node with a given value -> Time complexity: O(n)
For deletion, following any of the above-mentioned cases, we just need to free the extra node after disconnecting it from the list. Before that, we overwrite the current connection and create new connections. This is how we delete a node from our desired place.
Syntax for freeing a node:
free(ptr);
The above syntax will free the node, removing its reserved location in the heap.
Now, let's begin with each of these cases of insertion.
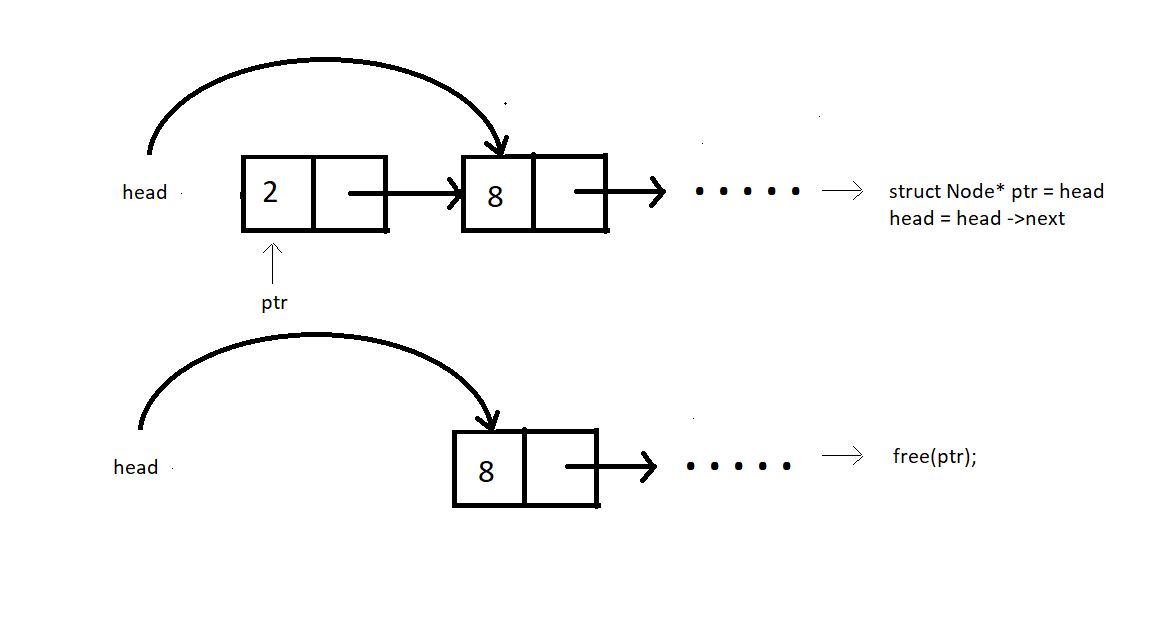
Case 1: Deleting the first node.
For deleting the first node in a linked list, we need to follow a few steps to ensure the operation is performed correctly. First, we need to update the head pointer to point to the second node in the list. This is done by setting the head to head->next. By doing this, we effectively remove the first node from the list's chain of connections.
Next, we need to free the memory allocated to the original head node to prevent memory leaks. This is achieved using the
freefunction. Here is a more detailed breakdown of the steps involved:Update the Head Pointer: Set the head pointer to the next node in the list. This is done with the statement
head = head->next;. This step ensures that the list now starts from the second node.Free the Original Head Node: Use the
freefunction to deallocate the memory of the original head node. This is done with the statementfree(original_head);. This step is crucial to avoid memory leaks.
Here is a detailed code example for deleting the first node in a linked list:
struct Node deleteFirst(struct Node head){
struct Node * ptr = head;
head = head->next;
free(ptr);
return head;
}
In this code, we first check if the list is empty. If it is, we simply return NULL as there is nothing to delete. Otherwise, we store the original head node in a temporary pointer, update the head to the next node, and then free the memory of the original head node. Finally, we return the new head of the list.
Case 2: Deleting at some index in between:
Assuming the index starts from 0, we can delete an element from index i > 0 as follows:
First, create a temporary pointer
pthat points to the node just before the one you want to delete in the linked list. This ensures that you have access to the node preceding the target node.For example, if you want to delete the node between nodes with values 2 and 8, move the pointer
pto the node with value 2. This step is crucial as it sets up the correct position for the deletion operation.Assume that
ptris a pointer that points to the node you want to delete. This node is the one immediately after the node pointed to byp.Update the
nextpointer of the node pointed to bypto skip over the node pointed to byptrand point directly to the node afterptr. This effectively removes the target node from the linked list.Finally, free the memory allocated to the node pointed to by
ptr. This step ensures that there are no memory leaks and that the node is properly deleted from the list.
Here is a detailed code example for deleting a node at a specific index in a linked list:
struct Node deleteAtIndex(struct Node head, int index){
struct Node * p = head;
struct Node q = head->next;
for (int i = 0; i < index-1; i++) {
p = p->next;
q = q->next;
}
p->next = q->next;
free(q);
return head;
}
In this code, we first check if the list is empty or the index is invalid. If the index is 0, we delete the head node as described earlier. For other indices, we move the pointer p to the node just before the target node. We then update the next pointer of p to skip the target node and free the memory of the target node. Finally, we return the updated head of the list.
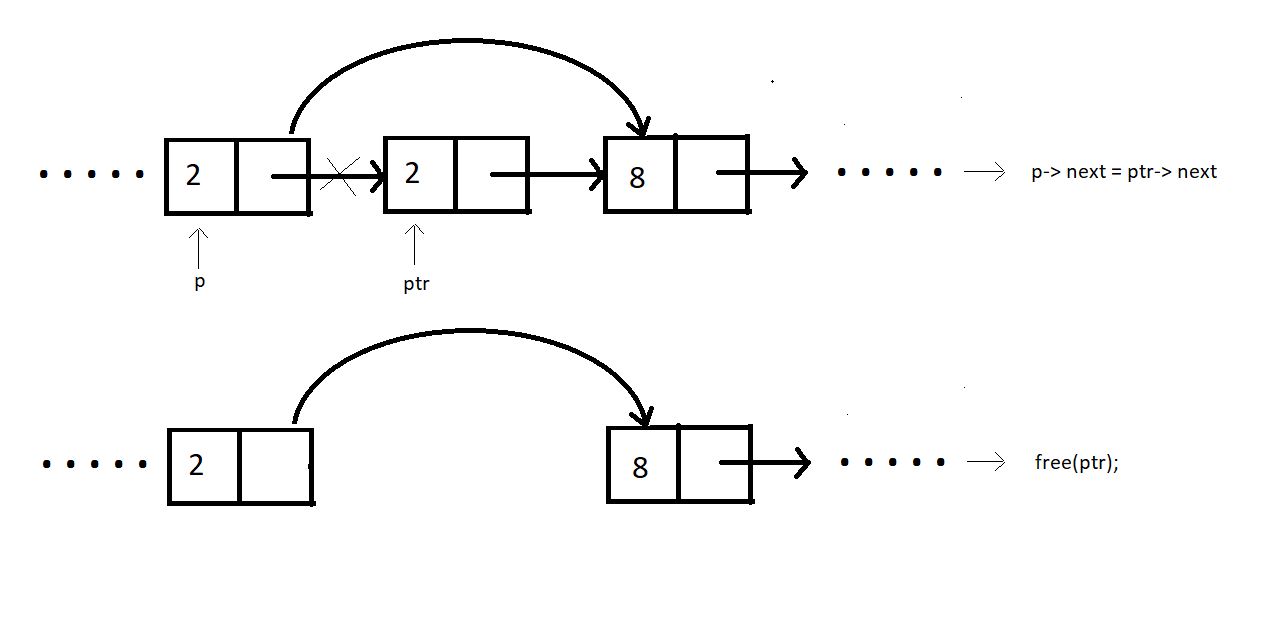
Case 3: Deleting the last node.
To delete an element at the end of the linked list, we need to follow a few steps carefully. First, we create a temporary pointer named ptr and set it to point to the last element of the list. Additionally, we create another pointer named p and set it to point to the second-to-last element in the list.
We then update the next pointer of the second-to-last element (p) to point to NULL, effectively removing the last element from the list. This step is crucial because it ensures that the linked list is properly terminated and that there are no dangling pointers.
After updating the next pointer, we free the memory allocated to the ptr pointer. This step is essential to prevent memory leaks, which can occur if the memory allocated to the deleted node is not properly released.
Here is a detailed code example for deleting the last node in a linked list:
struct Node deleteAtLast(struct Node head){
struct Node* p = head;
struct Node* q = head->next;
while(q->next !=NULL) {
p = p->next;
q = q->next;
}
p->next = NULL;
free(q);
return head;
}
In this code, we first check if the list is empty. If it is, we simply return the head as there is nothing to delete. If the list has only one node, we free the head node and return NULL, indicating that the list is now empty.
For lists with more than one node, we traverse the list using the pointer p until we reach the second-to-last node. We then set the next pointer of p to NULL, effectively removing the last node. Finally, we free the memory allocated to the last node (ptr) and return the updated head of the list.
By following these steps, we ensure that the last node is properly deleted and that the linked list remains in a consistent state.
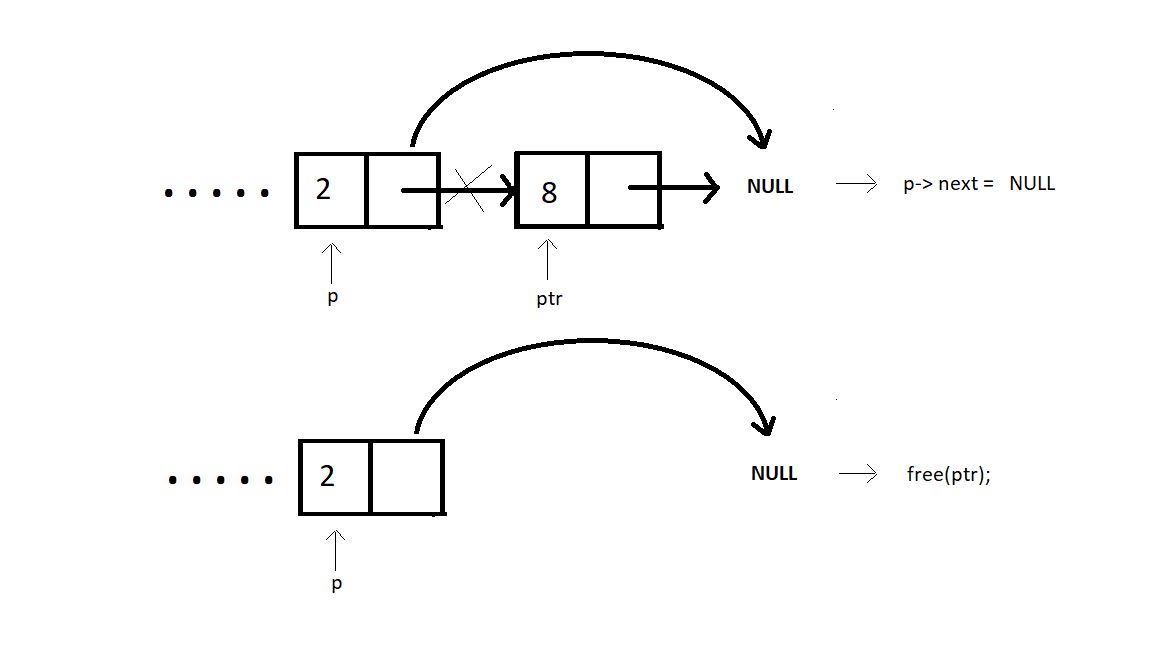
Case 4: Delete the first node with a given value:
Similar to the other cases, a node with a given value can be deleted by following a few detailed steps:
First, we need to find the node that contains the given value. We can do this by traversing the linked list starting from the head node. We use a pointer, let's call it
current, to iterate through the list. We also need a pointerprevto keep track of the previous node as we traverse the list.If the head node itself holds the given value, we need to handle this special case separately. In this case, we simply update the head to point to the next node and free the memory allocated to the original head node.
For other cases, we continue traversing the list until we find the node that contains the given value. Once we find this node, we update the
nextpointer of the previous node (prev) to point to the node after the node to be deleted (current->next). This effectively removes the node with the given value from the list.Finally, we free the memory allocated to the node containing the given value to avoid memory leaks.
Here's a more detailed code example for deleting the first node with a given value:
struct Node deleteByValue(struct Node head, int value){
struct Node *p = head;
struct Node *q = head->next;
while(q->data!=value && q->next!= NULL) {
p = p->next; q = q->next;
}
if(q->data == value){
p->next = q->next;
free(q);
}
return head;
}
By following these steps, we ensure that the node with the given value is properly deleted and that the linked list remains in a consistent state. This approach handles both the special case where the head node contains the given value and the general case where the node to be deleted is somewhere else in the list.

Circular Linked List
A circular linked list is a linked list where the last element points to the first element (head), forming a circular chain. There is no node pointing to NULL, meaning there is no end node. In circular linked lists, we have a head pointer, but there is no clear starting point.
Refer to the illustration of a circular linked list below:
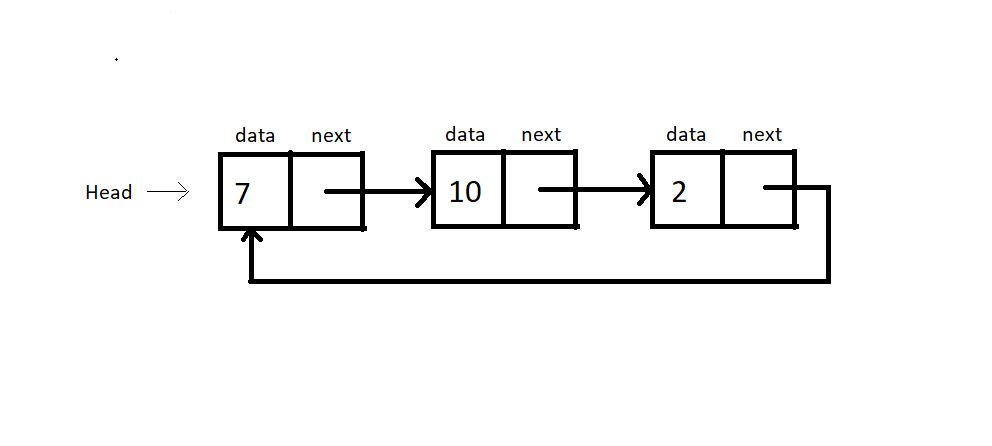
Operations on a Circular Linked List:
Operations on circular linked lists can be performed exactly like a singly linked list. It’s just that we have to maintain an extra pointer to check if we have gone through the list once.
Traversal:
Traversal in a circular linked list can be achieved by creating a new struct Node* pointer p, which starts from the head and goes through the list until it points again at the head. So, this is how we go through this circle only once, visiting each node.
And since traversal is achieved, all the other operations in a circular linked list become as easy as doing things in a linear linked list.
One thing that may have sounded confusing to you is that there is a head but no starting of this circular linked list. Yes, that is the case; we have this head pointer just to start or incept in this list and for our convenience while operating on it. There is no first element here.
Creating the circular linked list:
Creating a circular linked list is no different from creating a singly linked list. One thing we do differently is that instead of having the last element to point to NULL, we’ll make it point to the head.
Refer to those previous tutorials while creating these nodes and connecting them. This is the third time we are doing it, and I believe you must have gained that confidence.
struct Node {
int data;
struct Node *next;
};
int main(){
struct Node head;
struct Node second;
struct Node third;
struct Node fourth;
// Allocate memory for nodes in the linked list in Heap
head = (struct Node* )malloc(sizeof(struct Node));
second = (struct Node *)malloc(sizeof(struct Node));
third = (struct Node *)malloc(sizeof(struct Node));
fourth = (struct Node )malloc(sizeof(struct Node));
// Link first and second nodes
head->data = 4;
head->next = second;
// Link second and third nodes
second->data = 3;
second->next = third;
// Link third and fourth nodes
third->data = 6;
third->next = fourth;
// Terminate the list at the third node
fourth->data = 1;
fourth->next = head;
return 0;
}
Traversing the circular linked list:
Create a void function linkedListTraversal and pass the head pointer of the linked list to the function.
In the function, create a pointer ptr pointing to the head.
Run a do-while loop until ptr reaches the last node, and ptr-> next becomes head, i.e. ptr->next = head. And keep printing the data of each node.
So, this is how we traverse through a circular linked list. And do-while was the key to make it possible.
void linkedListTraversal(struct Node *head){
struct Node ptr = head;
do{
printf("Element is %d\n", ptr->data);
ptr = ptr->next;
}while(ptr!=head);
}
Now, assign ptr to the next of p, i.e.p->next = ptr. And head to the next of ptr, i.e. ptr->next = head.
- Now, the new head becomes ptr. head = ptr.**Inserting into a circular linked list:**
I’ll just cover the insertion part, and that too on the head. Rest of the variations, I believe, you’ll be able to do yourselves. Things are very similar to that of singly-linked lists.
Create a struct Node* function insertAtFirst which will return the pointer to the new head.
We’ll pass the current head pointer and the data to insert at the beginning, in the function.
Create a new struct Node* pointer ptr, and assign it a new memory location in the heap. This is our new node pointer. Make sure you don't forget to include the header file <stdlib.h>.
Create another struct node * pointer p pointing to the next of the head. p = head-> next.
Run a while loop until the p pointer reaches the end element and p-> next becomes the head.
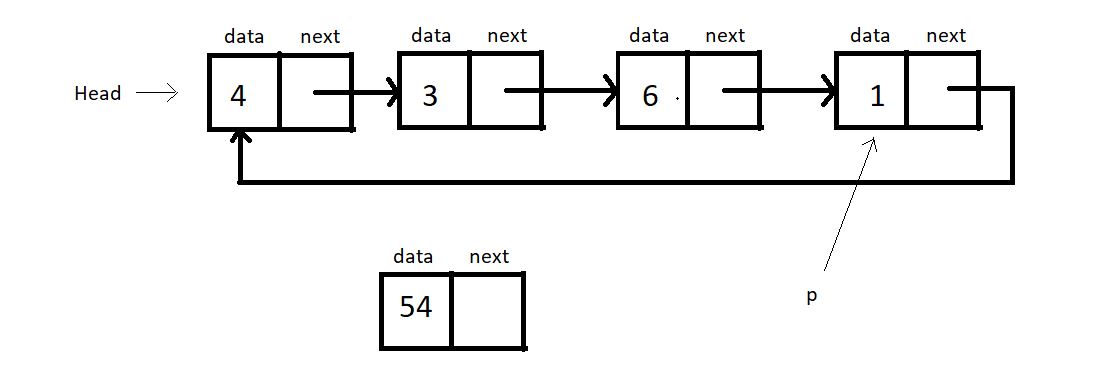
Now, assign ptr to the next of p, i.e.p->next = ptr. And head to the next of ptr, i.e. ptr->next = head.
Now, the new head becomes ptr. head = ptr.
Code of Inserting into a circular linked list
struct Node insertAtFirst(struct Node head, int data){
struct Node ptr = (struct Node ) malloc(sizeof(struct Node));
ptr->data = data;
struct Node * p = head->next;
while(p->next != head){
p = p->next;
}
// At this point p points to the last node of this circular linked list
p->next = ptr;
ptr->next = head;
head = ptr;
return head;
}
Doubly Linked Lists
What is a doubly-linked list?
Each node contains a data part and two pointers in a doubly-linked list, one for the previous node and the other for the next node.
Below illustrated is a doubly-linked list with three nodes. Both the end pointers point to the NULL.

How is it different from a singly linked list?
A doubly linked list allows traversal in both directions. We have the addresses of both the next node and the previous node. So, at any node, we’ll have the freedom to choose between going right or left.
A node comprises three parts, the data, a pointer to the next node, and a pointer to the previous node.
Head node has the pointer to the previous node pointing to NULL.
Implementation in C:
Let’s try implementing a doubly linked list in our codes. We’ll have a struct Node as before. The only information added to this struct Node is a struct Node* pointer to the previous node. Let’s name this prev.
This new information makes us travel in both directions, but using it follows the use of more memory space for a single node that now comprises three members. It is because of this we have a singly linked list.
Code of Implementation of a doubly linked list.
struct Node {
int data;
Struct Node* next;
Struct Node* prev;
};
Operations on a Doubly Linked List:
The insertion and deletion on a doubly linked list can be performed by recurring pointer connections, just like we saw in a singly linked list.
The difference here lies in the fact that we need to adjust two-pointers (prev and next) instead of one (next) in the case of a doubly linked list. It very much follows the fact, “With great power, comes great responsibility.” :)